Building Knowledge Graph Based on LLM
I am an AI and CMS developer, especially in Drupal/CMS, GrapesJS development.
With the rapid development of large models, the technical barrier for knowledge graphs is gradually lowering. Previously, extracting knowledge relationships was a core challenge of building a knowledge graph. Even if the user interface, business processes, graph data storage, and knowledge tagging were all perfectly constructed, the crucial issue of knowledge extraction lacked an excellent solution.
Currently, with the continuous upgrade of various large models and the improvement of intelligence, knowledge graphs built on large models and open-source architectures have become more operational, easier to implement, and able to extract knowledge accurately and efficiently.
This article focuses on the implementation approach of knowledge graphs based on large models and open-source architectures.
The overall architecture approach can be referenced in the diagram below.

The solution of knowledge graph building
Building a knowledge graph based on large models involves the following steps:
Feed data to the large model to extract knowledge relationships.
Retrieve the knowledge relationships and store them in a graph database.
Display the knowledge graph through a web frontend.
Overall, these steps are relatively simple, and the following diagram can be referenced:
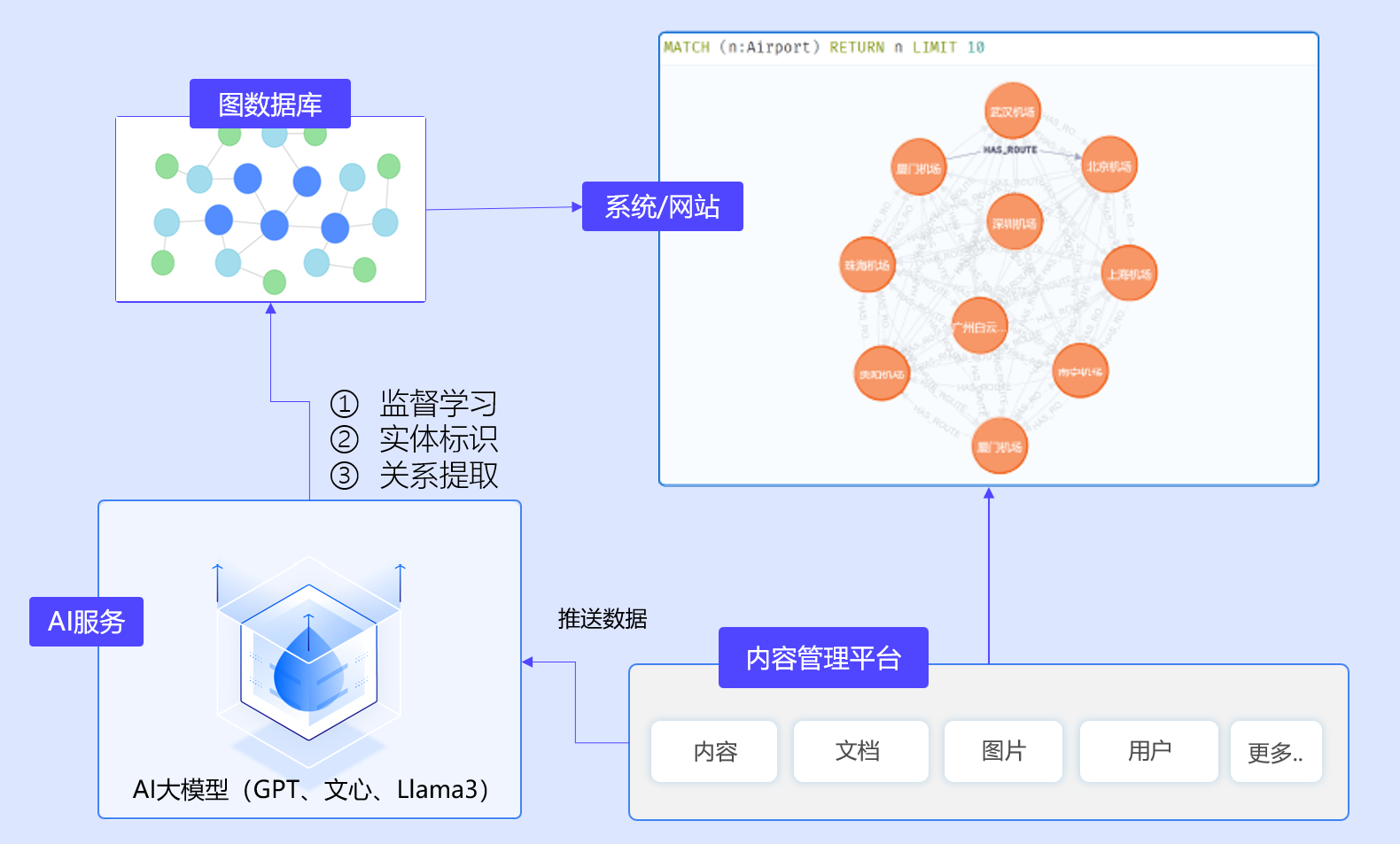
Next, let's discuss the implementation methods for each element in the process:
- Large Models
Large models can be externally sourced, such as OpenAI's ChatGPT, Baidu's Wenxin Yiyan, Alibaba's Tongyi Qianwen, and so on.
Alternatively, large models can be deployed locally using open-source models, commonly using tools like Ollama for deployment. Some popular open-source models include Llama3, Phi-3, etc.
- Graph Database
A graph database is not used for storing images, but for storing graph relationships, typically in the form of triplet data relationships such as A--(relationship)-->B. Common graph databases include Neo4J, Nebula Graph, GraphDB, etc.
Most graph databases are capable of storing knowledge graphs without any special requirements. We can choose any of these, or opt for those with higher market share and better community support, such as Neo4J or Nebula Graph.
- Web Display
Web display is typically implemented through JavaScript. While Neo4j offers its own web interface, using a unified open-source JS library provides more applications and flexible customization. After comparing many graph implementations, we recommend the following open-source JS libraries:
3.1 Graphvis
Note that it’s Graphvis, not Graphviz. Graphvis is an interactive graph data visualization library developed in native JavaScript. It is simple to use, highly efficient, and comes with a rich set of graph layouts and analysis algorithms. It also includes Chinese documentation and examples. The official website is http://www.graphvis.cn/

3.2 Cytoscape
Cytoscape is a well-established network graph visualization library, particularly used in areas such as network topology, biological molecule relationships, and other research applications. It has significant usage in the scientific community, and its strong community support makes it a reliable choice for various graph visualization tasks.

3.3 ECharts
ECharts is an open-source visualization library developed by the Baidu team. It provides a wide range of chart types, including line charts, bar charts, pie charts, scatter plots, radar charts, maps, candlestick charts, gauges, heatmaps, parallel coordinate charts, Sankey diagrams, funnel charts, box plots, and more.
The advantage of ECharts is its powerful functionality. However, its downside is also the same—its extensive feature set can make it overly complex and not specifically focused on network relationships or topological data. As a result, it can feel somewhat cumbersome for such specialized use cases.

3.3 Mermaid Chart
Mermaid has chart feature, and the source is plain text, so that is very easy to edit and update it. as well, we can find many online AI to generate mermaid chart, such as
mermaidchart, and ai graph maker

Conclusion
In summary, using the architecture outlined above, it is possible to quickly build a subject-specific knowledge graph. The advantage of using an open-source framework is that it is easy to extend and modify. However, the drawbacks include the difficulty in choosing from many available options, debugging challenges (which require professionals to resolve bugs), and the development costs.
Customization and Extension
The open-source framework offers flexibility for further customization and extension. You can integrate additional tools or modify the graph to meet specific needs. However, the sheer number of available options can sometimes make the choice of the right tool challenging, and debugging can require specialized expertise.Scalability and Maintainability
The open-source approach makes the system highly scalable, and you can add new knowledge sources or refine the existing graph without vendor lock-in. However, ongoing maintenance and debugging may require a dedicated team due to the complexity of the integration between various components.Development and Cost Considerations
While open-source frameworks provide flexibility, the development process can be time-consuming, especially when it comes to integrating large models and graph databases. Additionally, costs can arise from the need for professional development skills, debugging, and system maintenance.
We have also implemented a complete knowledge graph using Drupal CMS + large models + graph databases. If you need further details, you can contact the author via email.


